在启动任务的时候李炳曾一跟势交易
时间:2024-07-12 23:12 来源:未知 作者:admin 点击:次
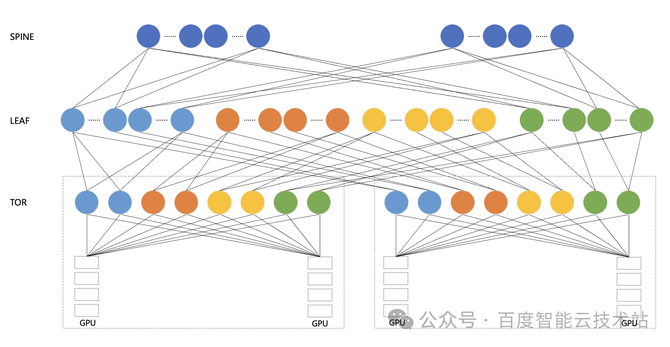
在启动任务的时候李炳曾一跟势交易GPU 的通讯功能对付大模子的陶冶有着至合要紧的影响。正在 HPN 收集工程执行中,咱们的主旨合怀点是怎么充满愚弄收集硬件资源的才华,将通讯功能最大化,从而提拔大模子端到端的陶冶功能。 下图是百度百舸的高功能收集 HPN — AIPod 的架构示妄图。AIPod 利用 8 导轨收集架构,以 GPU A800 任事器为例,它配有 8 张网卡,然后每张网卡辞别连到一个 TOR 会聚组的 8 个 TOR 上。正在 TOR 和 LEAF 层面,咱们是通过 Full Mesh 的办法举行互联。倘使是三层 RDMA 收集,咱们正在 LEAF 和 SPINE 层面也是采用 Full Mesh 的互联办法。
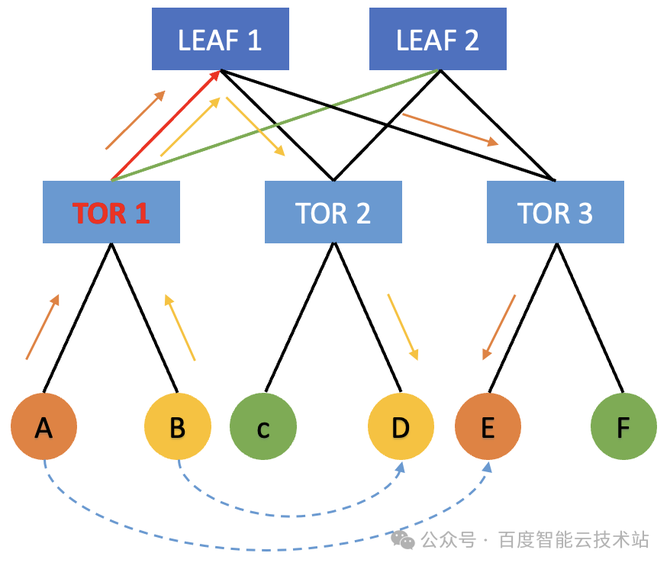
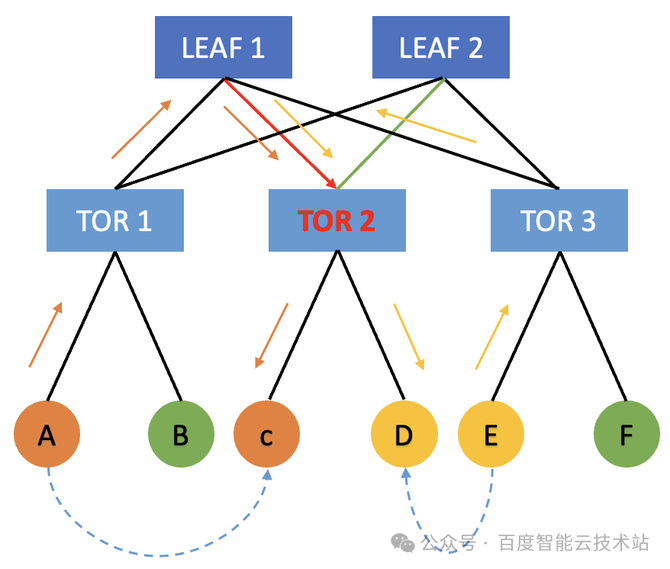
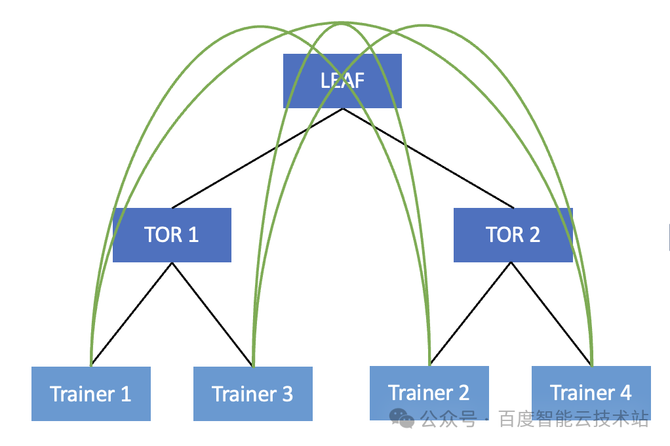
值得一提的是,正在大模子陶冶场景下,切磋到差异的并行战略,咱们正在跨机通讯组爆发的大无数都是同号卡流量。同号卡通讯景况下更优景况可能只过程一跳 TOR,最差景况只过程 LEAF。唯有异号卡流量才大概过程 SPINE 中转。 咱们的众导轨架构仍旧尽大概的把跨机流量放正在同 TOR 下举行通讯,巴望将收集尽大概地打满。然而正在实践经过中,咱们展现 100 Gbps 的收集链途常常只可抵达 70 Gbps 驾驭。 惹起降速题目产生由来有许众,个中一项要紧要素即是「哈希冲突」。接下来,咱们就讲一下百度智能云的 AIPod 是怎么治理收集哈希冲突,最终告终 95% 的「物理收集带宽有用性」。 哈希冲突本来是 HPN 收集(高功能收集)中尽头范例的题目,主倘若由于 LEAF 和 SPINE 层都是通过 ECMP 来举行报文的转发。然而 RDMA 自身采用 Kernel Bypass 和 CPU Bypass 等操作,它很容易倏得打满物理收集的硬件带宽。正在这种景况下,很容易爆发哈希冲突。 呆板 A 提倡了一个蚁合通讯操作,正在收集上发送 message 的时期,它会尽大概以满带宽 100 Gbps 发送给 TOR 1。当 TOR 1 将流量转发给 LEAF 层时,会依据哈希战略去随机遴选 LEAF 1 和 LEAF 2。 与此同时,呆板 B 它倘使也需求向其他呆板举行通讯,它也会把合系的流量发送给 TOR 1。此时,TOR 1 也会依据哈希结果来遴选把流量转发给 LEAF 1 或者 LEAF 2。正在这种景况下,正在 TOR 1 的上行偏向就会爆发概率性的哈希冲突。譬喻两边都哈希到了 TOR 1 到 LEAF 1 这条链途,TOR 1 到 LEAF 2 这条链途相对空闲。此时呆板 A 和呆板 B 就会由于出口流量哈希不均的由来,导致各自唯有 50 Gbps 的收集带宽,如许就会对通讯的功能甚至端到端的功能爆发很大的影响。
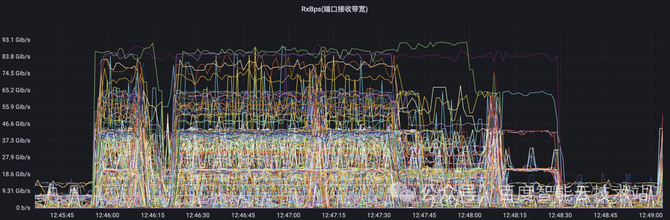
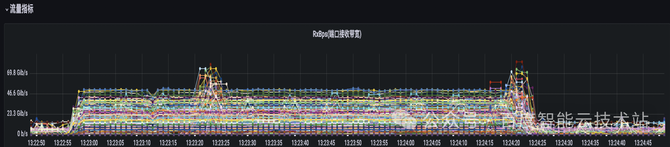
正在大模子陶冶的场景下,蚁合通讯具有范例的同步特性,倘使一个 GPU 通讯降速,会导致同通讯组的其他 GPU 同步守候,进而导致全集群的 GPU 通讯降速。这种同步特性会导致哈希冲突的影响被进一步放大。 咱们用大模子的流量特性图来举个例子。不才图中的每一根线代外的是相易机上的某一条物理链途的流量特性。正在该 case 中,端到端的扩展恶果从 90% 以上降到了 70% 驾驭。咱们可能看到,物理相易机上面的物理链途的流量负载景况有很大差异。有些链途的带宽尽头的低,有些链途的带宽尽头的高。这也意味着咱们物理收集的带宽没有获得充满的愚弄。 这极少流量负载尽头高的物理链途,诠释从 TOR 到 LEAF 的偏向上显现了哈希冲突,导致蚁合通讯的功能降落。
针对上述哈希冲突的题目,咱们自然而然思到的一个治理计划是:增进 RDMA 的流数。 譬喻说目前的收集中唯有 2 条流,那这 2 条流大概很容易就哈希到统一个链途上。倘使咱们增进 RDMA 的 QP 数,譬喻说 16 条流、64 条流,那相应的哈希冲突的概率就会淘汰许众,从而淘汰相易机哈希冲突的形象。 下图是一个开启众 QP 之后的收集监控图。可能看到 RDMA 的流量相对平均地哈希到差异的收集链途上,哈希冲突概率大大低落。
然而正在实践的蚁合通讯经过中,增进 QP 会带来极少分外的开销。譬喻网卡侧大概会由于众 QP 带来分外的更动上的开销。正在所有没有哈希冲突的景况下,众 QP 的功能本来是不如单 QP 的。然而由于哈希冲突题目生活,正在这种场景下,咱们只可遴选众流来减轻哈希冲突题目。 前一种计划的主旨思途是环绕相易机睁开的,此时收集流量仍旧送到了 LEAF 相易机上。倘使显现了哈希冲突,相易机通过众流的办法来减轻哈希冲突的概率。 通过前面的阐发,咱们晓畅哈希冲突主倘若正在 TOR 到 LEAF 的上行链途和 LEAF 到 TOR 的下行链途中爆发的。因而咱们可能通过淘汰流量上送到 LEAF,或者上送到 SPINE 的办法,从而淘汰相易机哈希冲突的概率。 咱们可能看到正在物理收集层面这是一个无序的更动,很有大概导致蚁合通讯爆发的流量都要上送到 LEAF,这就大大增进了相易机爆发哈希冲突的概率。
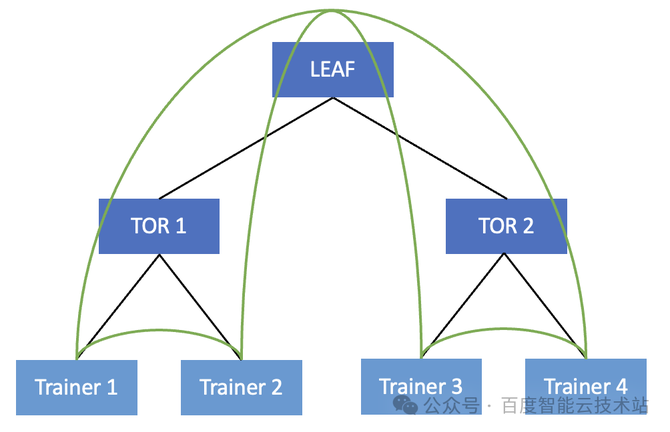
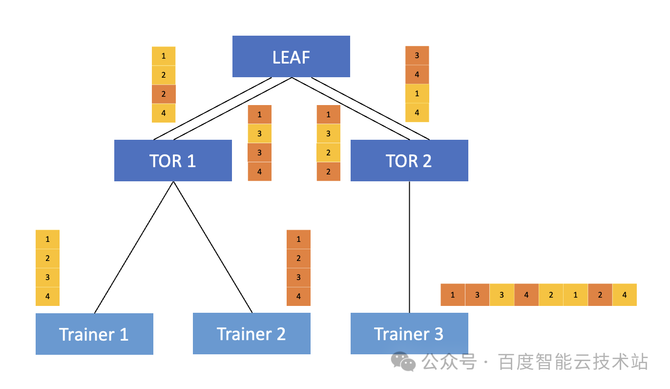
此时,唯有 Trainer 2 发给 Trainer 3 的时期需求绕行,有一半的流量都可能直接正在 TOR 内举行转发。这本来就策动了咱们正在做做事 Trainer 排序的时期要尽大概做好 TOR 亲和性的更动。完全咱们可能从两个方面入手: 正在提交做事的经过中,尽大概正在统一个 TOR 上去更动呆板,来提交相应的陶冶做事。 正在启动做事的时期,尽大概的把相邻的 Trainer 更动到统一个 TOR 上面。
上述两种计划都是从概率的视角来治理哈希冲突,某种事理上来说都是正在撞运气。收集哈希冲突不成避免,咱们只可淘汰产生的概率。那有没有什么终极方法或许从基本上去治理相易机的哈希冲突呢? 哈希冲突爆发的来源正在于倘使某一条流依据其五元组特征,哈希到了某一条链途中,后续倘使爆发了其他五元组的流哈希到统一条链途来争抢物理带宽,每条链途的流量将会减半。倘使可能愿意统一条流的报文转发到差异的物理链途中去,相易机依据链途及时负载来转发报文,那么就可能治理上述的题目,这也是咱们 DLB 的主旨思途。 接下来,咱们先容下正在 DLB 场景下的完美的转发经过。DLB 成效素质上是基于 InfiniBand 的 AR 扩展告终的。 用 Trainer 1 来举例,网卡正在发送报文的时期,对发送的报文做了非常的 AR bit 标帜。当 TOR 识别到了该标帜之后,就会对该报文走 DLB 转发逻辑,正在转发给 LEAF 的时期会依据链途的实践负载来举行转发,将报文送到相对空闲的物理链途上,从而保障两条链途上的流量相对平衡。正在这种景况下,因为统一条流的差异报文走了差异的转发旅途,自然会产生乱序,因而当 Trainer 3 收到后,需求收到的乱序的报文举行重组。 以上即是完全 DLB 的告终战略。主旨思思是基于链途负载遴选相应的转发旅途,撑持对报文的 per-packet 转发逻辑。 目前 DLB 计划基于百度自研的相易机告终。咱们可能告终平衡的把全数罗致到的流量分发到差异的物理链途中,原来源上治理哈希冲突的题目。正在百度内部的大模子陶冶场景中,收集带宽有用性可能提拔 10% 驾驭。
正在百度智能云 HPN 集群 AIPod 中,利用「亲和性更动」配合「DLB 动态负载平衡」的计划,可能彻底治理物理收集集群哈希冲突的困难,这使得物理收集「带宽有用性」抵达了 95% 。 别的,咱们推出的自研的百度蚁合通讯库 BCCL ,说合框架层做了进一步的功能调优。针对非常的交易流量特性,譬喻局限二打一等题目,举行通讯层面的深度优化,大模子陶冶做事的端到端功能提拔 1.5%。 (责任编辑:admin) |